
Contents
- Introduction
- Wave function
- Basic principles of quantum mechanics
- Spin
- Experimental evidence
- Mathematical description of spin
- Other operators and wave functions
Introduction
It is useful to divide physics, specifically mechanics (the study of motion and forces), into two main categories: classical and quantum mechanics.
When we think of classical mechanics, for most people, Newtonian mechanics comes to mind since that is what is usually taught in high school and as a first course in undergraduate physics. But there are other formulations – like the Lagrangian, Hamiltonian and Hamilton-Jacobi formulations. These “alternative” formulations actually are more easily relatable to quantum mechanics than the Newtonian formulation, and as we shall see later in this article, are actually more pertinent to this discussion. However, all of these formulations of classical mechanics have one thing in common: if we know the position and velocity (or momentum since momentum equals mass x velocity) of all of the particles in an ensemble of particles at a given time, we will know their position and velocities at all times in the future. A corollary to this is that, if we have complete knowledge of the state of a system at one time, we can theoretically predict the results of any future event, including results of experiments, with certainty.
By contrast, in quantum mechanics, per the Heisenberg uncertainty principle, the position and velocity of a particle cannot be both known definitively at the same time. If the position is known definitively then the we can’t know the velocity(momentum) and visa vera. Similarly, the results of individual experiments cannot be predicted definitively. Instead, only the probability of an outcome can be predicted before an experiment is run. However, if the experiment is performed a large number of times, the percentages of occurrence of various outcomes approaches those predicted by classical mechanics.
Wave function
Newton developed his system of mechanics by looking at experimental results and developing equations to fit the data. Likewise, a mathematical framework was developed to fit the experimental findings in quantum mechanics.
One of the primary mathematical tools used to describe quantum mechanical phenomena is the wave function. The wave function is basically a vector or vector-like mathematical object such as a function that describes the state of a quantum mechanical system given a specific basis. Vectors, in the traditional sense of a finite collection of numbers, are used when we’re working with discrete variables like values of electron spin. Functions are used when working with continuous variables like particle position. Let’s consider traditional vectors because they convey the basic concepts better. Each component that makes up the wave function vector is called a probability amplitude and is a complex number. Each probability amplitude relates to (but is not the same thing as) the probability of a specific measurement occurring. To get the actual probability, we need to multiply the probability amplitude by its complex conjugate. The reason that complex numbers are used is not simple to explain. However, the basic idea is that quantum mechanics deals with waves that not only have magnitude but also have phase. It is this phase factor that leads to constructive and destructive interference of these waves which leads to the very different behavior of quantum objects as compared with classical objects. The use of complex numbers introduces this phase factor. (Think of the hand of a clock pointing in various directions. The length of the hand represents the magnitude of a vector. The directions in which the hand points represents the phase. However, no matter in which direction the hand points, its length, i.e., magnitude, remains the same.)
Basic principles of quantum mechanics
Many of the additional key points of the mathematical framework of quantum mechanics can be expressed in a group of four principles or postulates. Linear algebra plays a significant role in these postulates. We will state them first then attempt to explain them after. Most of this discussion comes from an excellent book written by renowned Stanford physicist Leonard Susskind and his coauthor Art Friedman, geared toward the interested amateur. The book can be obtained at the following link:
https://www.amazon.com/Quantum-Mechanics-Theoretical-Leonard-Susskind/dp/0465062903/
Susskind also has a fantastic series of lectures on physics called The Theoretical Minimum. It the can be found here.
Getting back to our subject, the 4 postulates of quantum mechanics are:
- The observable or measurable quantities of quantum mechanics (like spin, position, momentum and energy of particles) are represented by linear operators. These are essentially Hermitian matrices, mathematical objects that fall within the subject of linear algebra.
- The possible results of a measurement are the eigenvalues,
 , of the operator that represents an observable. The state for which the result of a measurement is unambiguously is the corresponding eigenvector,
, of the operator that represents an observable. The state for which the result of a measurement is unambiguously is the corresponding eigenvector,  .
. - Unambiguously distinguishable states are represented by orthogonal vectors.
- If
 is at the state vector of a system, and the observable
is at the state vector of a system, and the observable  is measured, the probability to observe measurement value is
is measured, the probability to observe measurement value is
![\[ P(\lambda_i) = \braket{A}{\lambda_i} \braket{\lambda_i}{A} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-4bb2be48eb204aca2fe685c59ce41e68_l3.png "Rendered by QuickLaTeX.com")
Spin
We will use the spin of an electron as an example to illustrate how the above-described mathematical machinery works.
Electron spin is a purely quantum phenomenon that has no direct correlate with classical mechanics. The closest we can come to a classical model for spin is to think of a charged particle spinning on its central axis, creating a magnetic field and acting as a tiny bar magnet. If we were to curl our second through fifth fingers in the direction of a particle’s rotation, the direction in which our thumb points would give us the direction of the north pole of the little bar magnet. (This is called the right-hand rule.) Mathematically, the closest classical approximation we have to spin is to consider it like rotational angular momentum intrinsic to a charged particle. Spin is the property that determines behavior of a particle in a magnetic field. Just as there are two directions in which a particle can spin, there are two (and only two) values that the spin of an electron can take: spin up and spin down. We’ll explain this in a minute.
If we place the electron in a constant external magnetic field, the electron, in terms of classical mechanics, will orient itself such that its north pole aligns with the direction of the magnetic field and its south pole against it. In quantum mechanical terms, if the electron spin is aligned with the magnetic field, it is spin up. If it is aligned opposite the magnetic field, it is spin down.
Now suppose we have an apparatus that can measure whether the electron is spin up or spin down. Details about how such an apparatus might accomplish this can be found here, but we won’t worry about that now. For our current purposes, we’ll just assume that it works. We also have a second apparatus that creates a magnetic field, causes an electron spin to align with its magnetic field (called preparing an electron), then transfers it to the measuring apparatus. (Again, for our purposes, it’s not important how this is carried out.) In what follows, we’ll assume that our electrons and our machines are located in a standard Cartesian coordinate with 3 orthogonal axes (i.e., oriented at right angles to one another) which we’ll call  ,
,  and
and  .
.
Experimental evidence
We’re going to start by considering the results of some experiments performed on the above-described equipment then we’ll try to come up with some equations that describe the data.
The axis conventions we’ll use for these experiments are as follows:
- The plain of this page is the
 plane.
plane. - The axis goes in and out of this paper.
- The
 direction is up; the
direction is up; the  direction is down.
direction is down. - The
 direction is to the right; the
direction is to the right; the  direction is to the left.
direction is to the left. - The
 direction is away from us; the
direction is away from us; the  direction is toward us.
direction is toward us.
First, prepare an electron with its spin up in the -direction. Send it over to our measuring apparatus and measure it in the -direction. If the spin is aligned with the magnetic field (i.e., it is spin up) then the apparatus will measure +1. If the spin is aligned against the magnetic field (i.e., it is spin down), then the apparatus will measure -1. Since the electron we prepared is spin up, the apparatus will measure +1, with 100% certainty. Another way of stating this is: if we prepare an infinite number of electrons in the spin up configuration, then every time we measure, our apparatus will measure +1. If we prepare another electron spin down, our apparatus will measure -1 with 100% certainty.
But what happens if we prepare the spin with its north pole pointing in the -direction of space and measure with our apparatus pointing in the -direction of space? Then with 50% probability, our apparatus will measure +1 and with 50% probability, it will measure -1. Said another way, if we prepare an infinite number of electrons with spin in the -direction and measure them with our apparatus oriented in the direction, then 50% of the time our apparatus will measure +1 and 50% of the time, our apparatus will measure spin down. If we repeat the experiment a large but less than an infinite number of times, the results will approach a 50-50 split between +1 and -1 measurements.
If we prepare our spin at an angle of  from the -axis toward the -axis and measure along the axis, approximately 93.3% of the time, we will measure +1 and approximately 16.7% of the time we will measure -1.
from the -axis toward the -axis and measure along the axis, approximately 93.3% of the time, we will measure +1 and approximately 16.7% of the time we will measure -1.
Mathematical description of spin
Now for the mathematics that represent these results.
First, we said that the state of a system is specified by a state vector. If we specify a basis for the vector space we’re working with, then that state vector would represent a wave function. The basis for the vector space is determined by the measurement that we want to make. For example, suppose our measurement apparatus is oriented along the -axis and will measure spin up (i.e., +1) if an electron’s north pole is oriented in the direction. Then the basis we will be measuring in we might call the basis. If a spin’s north pole is oriented in direction, then it will be measured as  100% of the time in this basis and its state will be referred to as
100% of the time in this basis and its state will be referred to as  . If, on the other hand, a spin’s north pole is oriented in direction, then it will be measured as
. If, on the other hand, a spin’s north pole is oriented in direction, then it will be measured as  100% of the time in this basis and its state will be referred to as
100% of the time in this basis and its state will be referred to as  .
.
The state vector (call it  ) can be represented as
) can be represented as
![\[ \ket{A}=\alpha_u\ket{u}+\alpha_d\ket{d} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-73e6ce91aebb2d9ef0361eed0710aa17_l3.png "Rendered by QuickLaTeX.com")
 is the probability amplitude for the spin being in state
is the probability amplitude for the spin being in state  is the probability amplitude for the spin being in state
is the probability amplitude for the spin being in state
Now
 is the complex conjugate of
is the complex conjugate of  is the complex conjugate of
is the complex conjugate of
In turn
 . This is the dot product of
. This is the dot product of  and which represents the component of probability amplitude of in the direction of .
and which represents the component of probability amplitude of in the direction of . . This is the dot product of
. This is the dot product of  and which represents the component of probability amplitude of in the direction of .
and which represents the component of probability amplitude of in the direction of .
Thus, if
 represents the probability of spin being spin up
represents the probability of spin being spin up represents the probability of spin being spin down
represents the probability of spin being spin down
then


For some intuition as to why this is so, click :
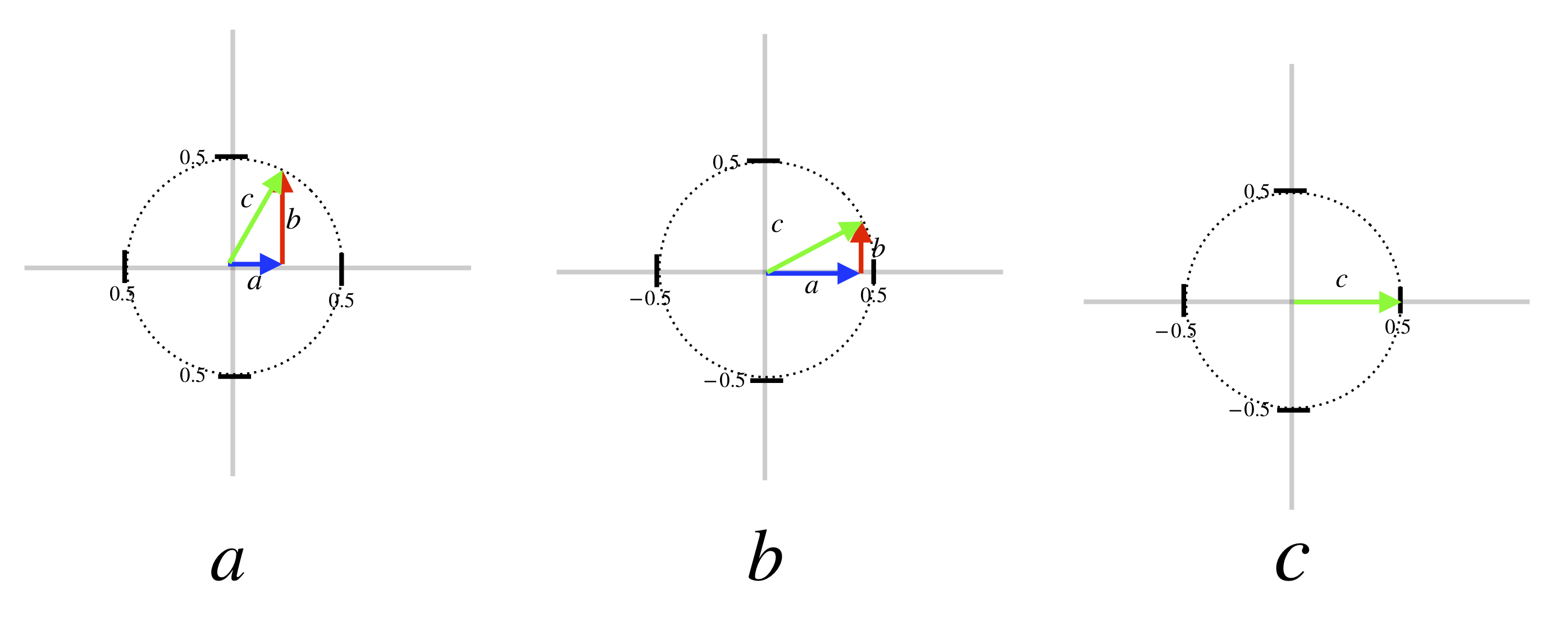
 is the length of the probability vector,
is the length of the probability vector,  with components of length
with components of length  and
and  . For simplicity, we’ll drop the formal notation and let
. For simplicity, we’ll drop the formal notation and let  ,
,  and
and  From the Pythagorean theorem
From the Pythagorean theorem
 -component of
-component of 
 is
is  which is always a real number. For example, if
which is always a real number. For example, if  then
then  . So the square of such a complex number is
. So the square of such a complex number is
 is a real number which is a good thing since it’s a probability and no one knows what it would mean for a probability to be imaginary. Note that
is a real number which is a good thing since it’s a probability and no one knows what it would mean for a probability to be imaginary. Note that  in each case is
in each case is  . This is arbitrary but was chosen to remind us that such a probability vector must be less than or equal to 1, as will be discussed below.
. This is arbitrary but was chosen to remind us that such a probability vector must be less than or equal to 1, as will be discussed below.As we said, probability in quantum mechanics is represented by vectors. The entities that are represented along the axes of the coordinate system on which these vectors are constructed are probability amplitudes. They form the basis for the vector space of which these probability vectors are a part. In the case of the spins we’ve been talking about, spin up, for example, can be represented on one axis and spin down on the other, as shown in the diagram.
Since and ,
this is just a restatement of the fourth basic principle of quantum mechanics:

In this case, the eigenvector, , is either and . So


It should also be noted that the sum of all of the probabilities have to add to 1. That is,

If the reason for this is not clear, an explanation can be found .


Spin prepared in Z and measured in z
Now let’s move on to explaining some experimental results.
If we prepare an electron in the spin up position, then with 100% certainty, the spin will be measure as +1 by our apparatus. Therefore,




and


We could also say that  .
.
Another way to represent the state vectors described above is via a column vector with the top entry representing the probability amplitude associated with being spin up and the bottom column representing the probability amplitude associated with being spin down. Thus,
- If electron spin is up in the direction, then
![\ket{A}=\mqty[ 1\\0]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-acecc1e311dd9101381ab305fe60efa7_l3.png "Rendered by QuickLaTeX.com")
- If electron spin is down in the direction, then
![\ket{A}=\mqty [0\\1]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-25ebf7b2379d61fca035ca3be6b6dce3_l3.png "Rendered by QuickLaTeX.com")
Using the same conventions, if a spin is prepared with its north pole pointing in the direction and and our measuring device is oriented in the direction, then
![\ket{A}=\alpha_u\ket{u}+\alpha_d\ket{d}=0\ket{u}+1\ket{d}=\ket{d}=\mqty [0\\1]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-9685896684537e4a1c804dec6fe6bb2c_l3.png "Rendered by QuickLaTeX.com")






Note that quantum principle 3 states that  and
and  form an orthonormal basis. The “ortho” part of this expression means that these 2 vectors are orthogonal which means that their dot product should equal 0. If we check
form an orthonormal basis. The “ortho” part of this expression means that these 2 vectors are orthogonal which means that their dot product should equal 0. If we check
![\braket{d}{u} = \mqty[0 & 1]\mqty[1\\0]=1 \cdot 0 +0 \cdot 1 = 0+0=0](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f598b260939eb57ec969cf2c7b65583f_l3.png "Rendered by QuickLaTeX.com")
which confirms our supposition.
It may seem peculiar that  , the dot product between and is zero since
, the dot product between and is zero since
- the dot product is supposed to be zero only when two vectors are orthogonal
- orthogonal vectors are usually thought of as being oriented at
 to each other
to each other - but the spins represented by and appear to be oriented at
 to each other
to each other
Well, it is true that the spin up and spin down are oriented at to each other in space. However, the thing that’s being plotted on the axis and abscissa to get the probability vector is probability amplitude, not direction in space, and the axes for these probability amplitudes are orthogonal (i.e., can be thought of as being perpendicular to each other), as depicted in the diagram below:
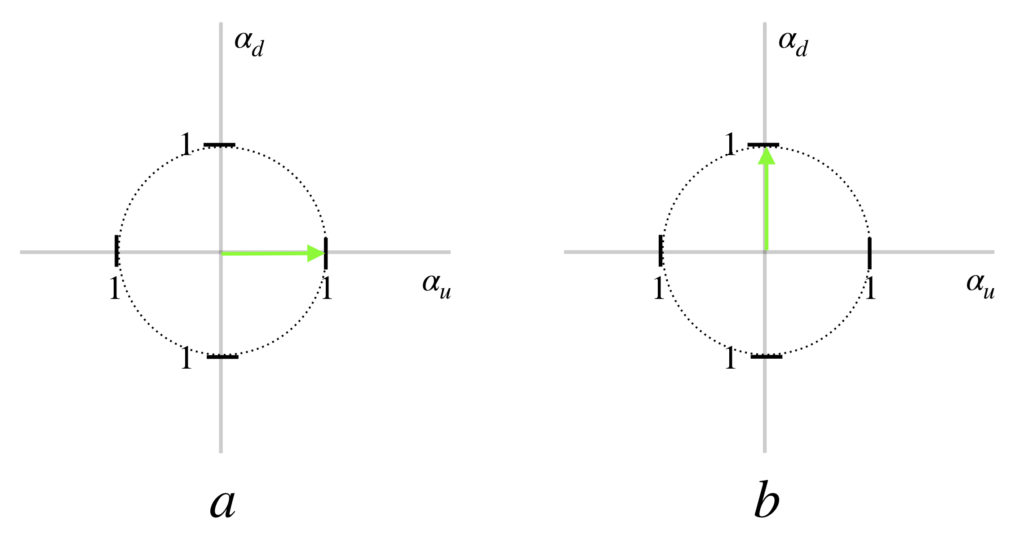
In the diagrams above, the entity described on the axes are probability amplitude. The probability amplitude associated with a spin being in the up spatial direction is purposely displayed on the horizontal axis to emphasize that what is being plotted here is not spatial direction. In a the probability amplitude is 100% spin up which means the probability of measuring the spin in the spin up direction is  (i.e., 100%). In b, the probability amplitude is 100% spin down which means the probability of measuring the spin in the spin down direction is (i.e., 100%).
(i.e., 100%). In b, the probability amplitude is 100% spin down which means the probability of measuring the spin in the spin down direction is (i.e., 100%).
Spin prepared in X and measured in x
We can have a discussion which is similar to the one we just had if an electron spin is prepared in the direction, leading to state  , and our measuring device is oriented in the direction. If this is so, then
, and our measuring device is oriented in the direction. If this is so, then
- means that electron spin is oriented in the with 100% certainty
-
 means that electron spin is oriented in the with 100% certainty
means that electron spin is oriented in the with 100% certainty
and
![\[ \ket{A}=\alpha_r\ket{r}+\alpha_l\ket{l} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-cde2c41eb414c9e3dae5aa316eadad9a_l3.png "Rendered by QuickLaTeX.com")
 is the probability amplitude for the spin being in state
is the probability amplitude for the spin being in state  is the probability amplitude for the spin being in state
is the probability amplitude for the spin being in state
Analogous to the previous case
 is the complex conjugate of
is the complex conjugate of  is the complex conjugate of
is the complex conjugate of
If
 represents the probability of spin being spin up
represents the probability of spin being spin up represents the probability of spin being spin down
represents the probability of spin being spin down
then


If we prepare an electron in the spin up position, then with 100% certainty, the spin will be measure as +1 by our apparatus. Therefore,




and


We could also say that 
If we prepare a spin in the direction and measure in the direction, then by arguments similar to the case where a spin is prepared in the direction and measured in the direction:



spin prepared in x and measured in z
Next, let’s prepare a spin in the direction and measure it in the direction. Preparation in the direction leads to state which means that, with 100% certainty, the spin has its north pole pointing in the direction. Since we’re measuring in the basis, the wave function of that describes the state of our spin has got to be expressed in the basis (i.e., as a linear combination of and ). To fit the data from experimental results, the state of our spin must be
![\[ \ket{A}=\frac{1}{\sqrt{2}}\ket{u}+\frac{1}{\sqrt{2}}\ket{d} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-65f28297a499dc52e8c08dab7dd01c0d_l3.png "Rendered by QuickLaTeX.com")
This means that
- The probability amplitude associated with the spin being measured as is

- The probability amplitude associated with the spin being measured as is

Since , the probability of the measurement being is given by
![\[ P_u=\alpha_u^*\alpha_u \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-d67b2dfbb764942f06880be64e53bb25_l3.png "Rendered by QuickLaTeX.com")
then
![\[ P_u=\frac{1}{\sqrt{2}}\frac{1}{\sqrt{2}}=\frac{1}{2} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-c1ed0eb8a0607482beeb2b924a5724a0_l3.png "Rendered by QuickLaTeX.com")
For a spin prepared in the direction leading to state and measured in the direction, again, 50% of the time we will measure +1 and 50% of the time, -1. An equation that fits this data is

The reason for the minus sign is that, like and ,  and
and  form an orthonormal basis which means that their dot product equals zero. The only way that this can happen is if
form an orthonormal basis which means that their dot product equals zero. The only way that this can happen is if  . Here is the calculation:
. Here is the calculation:

Because and form an orthonormal basis
- and are orthogonal
 their dot product is zero:
their dot product is zero:
- and are normalized their dot product is 1:
![\braket{u}{u} = \mqty[1&0]\mqty[1\\0] = 1 + 0 = 1\text{;}\quad\braket{d}{d} =\mqty[0&1]\mqty[0\\1] = 0 + 1 = 1](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-343c1e23d39e9c633a06b509e8687428_l3.png "Rendered by QuickLaTeX.com")
Therefore,

So
From this, we know that the probability amplitude associated with a -1 measurement is

Thus,

spin prepared at 30 ° from z and measured in z
So what happens if we prepare a spin with spin up in a direction  clockwise from the -axis in the plane and measure in the direction? This is a little more involved and will first require a discussion of linear operators, eigenvalues and eigenvectors. To understand this discussion, one needs to have a basic understanding of linear algebra. The previous section on requisite mathematics offers a brief presentation of this topic. A more extensive discourse on linear algebra can be found here.
clockwise from the -axis in the plane and measure in the direction? This is a little more involved and will first require a discussion of linear operators, eigenvalues and eigenvectors. To understand this discussion, one needs to have a basic understanding of linear algebra. The previous section on requisite mathematics offers a brief presentation of this topic. A more extensive discourse on linear algebra can be found here.
Linear operators
Let’s begin by talking about linear operators. They are Hermitian matrices. They represent the entity to be measured. The eigenvalues of this matrix are the measurements. The eigenvectors of the linear operator matrix form the basis for a vector space. The eigenvectors also represent the quantum states that go along with each given measurement.
3 linear operators are associated with the measurement of electron spin, one for each spatial direction. We’ll call these  ,
,  , and
, and  . Let’s derive the expression for
. Let’s derive the expression for
Deriving σz
We know that the 2 possible measurements we can make are +1 and -1. So we know that the eigenvalues of are +1 and -1. We know that the +1 eigenvalue is associated with the state and -1 with . That means that and are the eigenvectors. We can represent these facts by 2 equations:
![\[ \mqty [(\sigma_z)_{11} & {(\sigma_z)}_{12} \\ {(\sigma_z)}_{21} & {(\sigma_z)}_{22}] \mqty [1 \\ 0] = +1\mqty [1 \\ 0] \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-9c6cba043d66a23e2fae78f72159e71b_l3.png "Rendered by QuickLaTeX.com")
and
![\[ \mqty[{(\sigma_z)}_{11} & {(\sigma_z)}_{12} \\ {(\sigma_z)}_{21} & {(\sigma_z)}_{22}] \mqty [0 \\ 1] = -1\mqty [0 \\ 1] \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-24a7f711ae34d244c4abad06b9bf1ac3_l3.png "Rendered by QuickLaTeX.com")
This gives us 4 equations with 4 unknowns:

Therefore,
![\[ \sigma_z = \mqty [1 & \,\,\,\,\,0 \\ 0 & -1] \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-cf0ace65c4f46ab000842c2e9da777d4_l3.png "Rendered by QuickLaTeX.com")
We can derive and in a similar fashion. We’ll start with
Deriving σx
Recall that when we prepared a spin in the direction and measured in the direction we measured and when we prepared a spin in the direction and measured in the direction we measured . These facts can be expressed mathematically as
![\[ \sigma_x \ket{r} = +1 \ket{r} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-d2769b6bf04fd106c7a2348589330eb5_l3.png "Rendered by QuickLaTeX.com")
and
![\[ \sigma_x \ket{l} = -1 \ket{l} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-829e23e4a637d75d18e0f605d76e63bf_l3.png "Rendered by QuickLaTeX.com")
where
 is the matrix we’re trying to find
is the matrix we’re trying to find is the state where the spin of the electron is definitely in the direction
is the state where the spin of the electron is definitely in the direction is the state where the spin of the electron is definitely in the direction
is the state where the spin of the electron is definitely in the direction
We know from our previous description of experiments that when we prepare an electron spin in the and measure in the direction, our apparatus measures +1 half the time and -1 half the time. So


The two equations above describe what are called linear superpositions. What it means, according to the standard (Copenhagen) interpretation of quantum mechanics, is that the spin of the electron is in an indeterminate state in which it is spin up and spin down simultaneously – a state in which it remains until it is measured. Then when it’s measured, it definitively assumes one of the two states, a phenomenon that is called the collapse of the wave function. This behavior of a particle one way while it isn’t being measured and another way when it is measured was one of the things that motivated Bohm to seek an alternative to the standard interpretation of quantum mechanics.
At any rate, returning to our equations, we substitute the appropriate column vectors for and . When we do, we get
![\ket{r} = \frac{1}{\sqrt 2}\mqty[1 \\ 0] + \frac{1}{\sqrt 2}\mqty[0 \\ 1]=\mqty[\frac{1}{\sqrt 2} \\ 0] + \mqty[0 \\ \frac{1}{\sqrt 2}]= \mqty[\frac{1}{\sqrt 2} \\ \frac{1}{\sqrt 2}]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-238e0b41994904b07fbcd0bca29fc0e5_l3.png "Rendered by QuickLaTeX.com")
![\ket{l} = \frac{1}{\sqrt 2}\mqty[1 \\ 0] + \frac{1}{\sqrt 2}\mqty[\,\,\,\,\, 0 \\ -1]=\mqty[\frac{1}{\sqrt 2} \\ 0] + \mqty[\,\,\,\,\, 0 \\ -\frac{1}{\sqrt 2}]= \mqty[\,\,\,\,\, \frac{1}{\sqrt 2} \\ -\frac{1}{\sqrt 2}]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-29d195b9dd6d7fc893ac3c1a6d10ddd7_l3.png "Rendered by QuickLaTeX.com")
We can use these facts to write 2 eigenvalue equations that look like this:
![\[\mqty [(\sigma_x)_{11} & {(\sigma_x)}_{12} \\ {(\sigma_x)}_{21} & {(\sigma_x)}_{22}] \mqty[\frac{1}{\sqrt 2} \\ \frac{1}{\sqrt 2}] = +1\mqty[\frac{1}{\sqrt 2} \\ \frac{1}{\sqrt 2}]\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-e33e0c4a07f2537836cf4141316db1d3_l3.png "Rendered by QuickLaTeX.com")
and
![\[\mqty[{(\sigma_x)}_{11} & {(\sigma_x)}_{12} \\ {(\sigma_x)}_{21} & {(\sigma_x)}_{22}] \mqty[\,\,\,\,\, \frac{1}{\sqrt 2} \\ -\frac{1}{\sqrt 2}] = -1\mqty[\,\,\,\,\, \frac{1}{\sqrt 2} \\ -\frac{1}{\sqrt 2}] \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-ddbe0ac33d3392db1d3161f419b26efe_l3.png "Rendered by QuickLaTeX.com")
We can translate these eigenvalue equations into 4 equations in 4 unknowns:

Add the first and third equations. That gives us

Substituting  back into the first equation gives:
back into the first equation gives:

Next, add the second and fourth equations. That yields

Divide both sides of this equation by  . That leaves
. That leaves

Substituting  back into the second equation gives:
back into the second equation gives:

Divide through by  . We get:
. We get:

Subtract 1 from both sides. We are left with

Putting it all together, we obtain an expression for  :
:
![\sigma_x}=\mqty[{(\sigma_x)}_{11} & {(\sigma_x)}_{12} \\ {(\sigma_x)}_{21} & {(\sigma_x)}_{22}]=\mqty[0&1\\1&0]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-8dd948472460511fc9f1ba8c428a6032_l3.png "Rendered by QuickLaTeX.com")
Deriving σy
Deriving  is more of a challenge, mainly because we must first derive expressions for
is more of a challenge, mainly because we must first derive expressions for
 – the spin state going into the page, along what we will consider the -axis
– the spin state going into the page, along what we will consider the -axis
and
 – the spin state coming out of the page toward us, along what we will consider the -axis.
– the spin state coming out of the page toward us, along what we will consider the -axis.
Expressions for |i> and |o>
As with a spin prepared in the or directions, if we prepare a spin in either the or direction and measure in the direction, then 50% of the time we will measure spin up (+1) and 50% of the time we will measure spin down (-1). Equations that describe such results are:

and
where  .
.
Notice that a portion of these expressions are complex. We’ve said that complex numbers are necessary to make the mathematical machinery of quantum mechanics work. The proof of this fact and the derivation of these equations is tedious. However, this proof and this derivation can be found by clicking .


 . This can be expressed mathematically as
. This can be expressed mathematically as

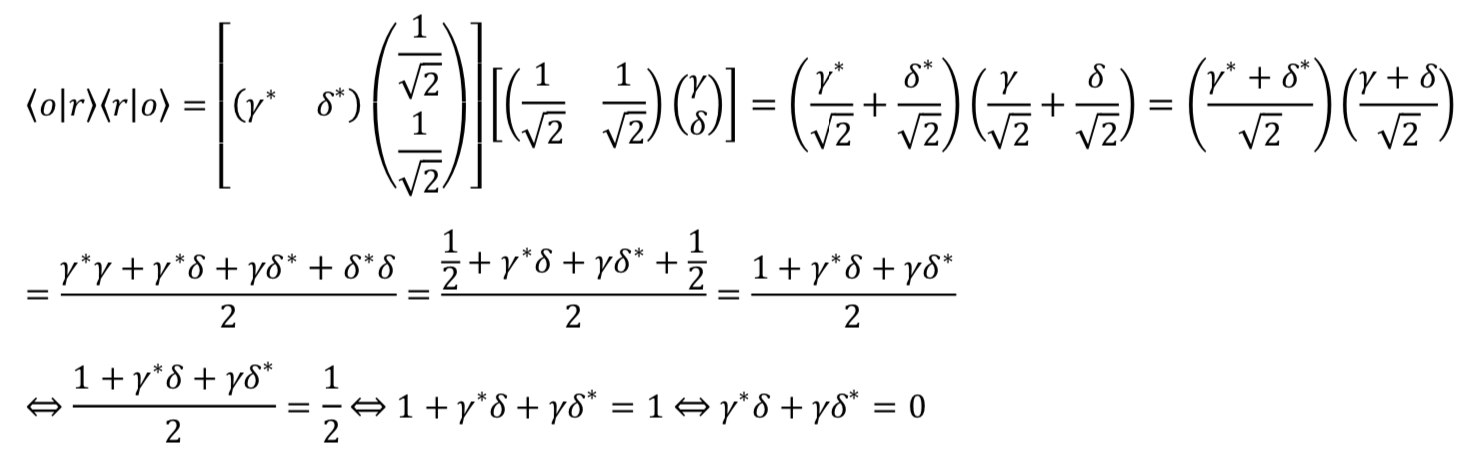
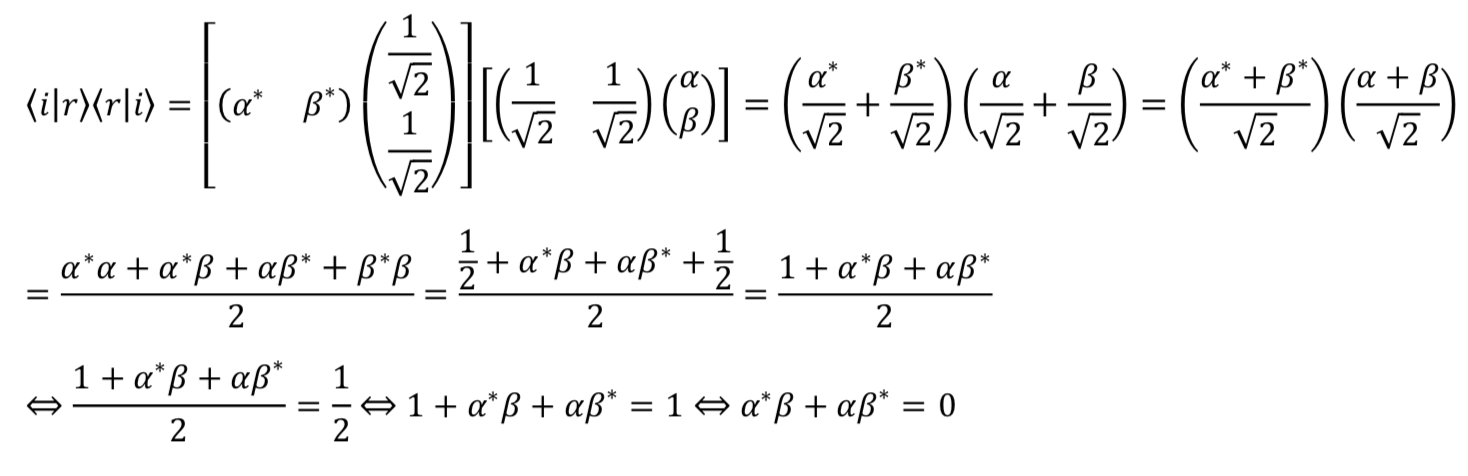
![\alpha^*\beta + \alpha\beta^* = 0 \quad \Rightarrow \quad \alpha^*\beta=-\alpha\beta^*=-[(\alpha^*\beta)^*]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f3f71481ccbc9f0e0cc6de2f631583f2_l3.png "Rendered by QuickLaTeX.com")
 with
with  . Then
. Then  .
.
 . So
. So  . That means that
. That means that  is purely imaginary.
is purely imaginary. is also purely imaginary.
is also purely imaginary. cannot both be real. And if
cannot both be real. And if  and
and  or
or  is imaginary. Let’s examine the case of
is imaginary. Let’s examine the case of  and
and  . Then
. Then  which is mixed imaginary.
which is mixed imaginary. and
and  . Then
. Then  which is real.
which is real. and
and  . Then
. Then  which is mixed imaginary.
which is mixed imaginary. (which incorporate imaginary numbers) fit the experimental data.
(which incorporate imaginary numbers) fit the experimental data.
If we examine all of these equations carefully, we can see that they describe known experimental data perfectly.
Using these expressions for  and
and  , we can now construct the linear operator for spin y, . The procedure is analogous to that used for finding the operators and .
, we can now construct the linear operator for spin y, . The procedure is analogous to that used for finding the operators and .
![\begin{array}{rcl} \ket{i}&=&\frac{1}{\sqrt 2}\ket{u}+\frac{i}{\sqrt 2}\ket{d}\\ &=&\frac{1}{\sqrt 2}\mqty[1\\0]+\frac{i}{\sqrt 2}\mqty[0\\1]\\ &=&\mqty[\frac{1}{\sqrt 2}\\0] + \mqty[0 \\ \frac{i}{\sqrt 2}]\\ &=&\mqty[\frac{1}{\sqrt 2}\\\frac{i}{\sqrt 2}] \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-3fa358ef6f3f83b0278b0702b44e6246_l3.png "Rendered by QuickLaTeX.com")
and
![\begin{array}{rcl} \ket{0}&=&\frac{1}{\sqrt 2}\ket{u}-\frac{i}{\sqrt 2}\ket{d}\\ &=&\frac{1}{\sqrt 2}\mqty[1\\0]-\frac{i}{\sqrt 2}\mqty[0\\1]\\ &=&\mqty[\frac{1}{\sqrt 2}\\0] - \mqty[0 \\ \frac{i}{\sqrt 2}]\\ &=&\mqty[\frac{1}{\sqrt 2} \\ -\frac{i}{\sqrt 2}] \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f06452be7e90fed0d2ebf555ea051fb8_l3.png "Rendered by QuickLaTeX.com")
Next, we use this information to write 2 eigenvalue equations:
![\[\mqty [(\sigma_y)_{11} & {(\sigma_y)}_{12} \\ {(\sigma_y)}_{21} & {(\sigma_y)}_{22}] \mqty[\frac{1}{\sqrt 2} \\ \frac{i}{\sqrt 2}] = +1\mqty[\frac{1}{\sqrt 2} \\ \frac{i}{\sqrt 2}]\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-7c5e8648dbb876043a63320d1076971d_l3.png "Rendered by QuickLaTeX.com")
and
![\[\mqty[{(\sigma_y)}_{11} & {(\sigma_y)}_{12} \\ {(\sigma_y)}_{21} & {(\sigma_y)}_{22}] \mqty[\,\,\,\,\, \frac{1}{\sqrt 2} \\ -\frac{i}{\sqrt 2}] = -1\mqty[\,\,\,\,\, \frac{1}{\sqrt 2} \\ -\frac{i}{\sqrt 2}] \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a5fa005fc868bb36f9049d6510db67ab_l3.png "Rendered by QuickLaTeX.com")
We can translate these eigenvalue equations into 4 equations in 4 unknowns:

Adding the first and third equations gives us:

Substituting back into the first equation gives:

Multiply both sides by  . We get:
. We get:

Next, add the second and fourth equations. That yields

We are left with

Multiply both sides of this equation by  . That leaves
. That leaves

Substituting  back into the second equation gives:
back into the second equation gives:

Divide through by  . That gives us
. That gives us

Subtract  from both sides. We get
from both sides. We get

So our matrix is:
![\sigma_y=\mqty[0&-i\\i&0]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-1c9da847002b0b17fc937ab9e0f0dc2a_l3.png "Rendered by QuickLaTeX.com")
Summary: Pauli matrices
To summarize, there are three matrices, called the Pauli matrices, that represent the 3 operators associated spin in the 3 spatial directions:  ,
,  , . As we have seen, they are:
, . As we have seen, they are:
![\sigma_z=\mqty[1&0\\0&-1] \quad \sigma_x=\mqty[0&1\\1&0] \quad \sigma_y=\mqty[0&-i\\i&0]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-057096b54ef12353900252637ce106af_l3.png "Rendered by QuickLaTeX.com")
As Susskind notes in his book
- Operators are things that we use to calculate eigenvalues and eigenvectors.
- Operators act on state vectors (which are abstract mathematical objects), not on actual physical systems.
- When an operator acts on a state vector, it produces a new state vector.
However, it is important to realize that operating on a state vector is not the same as making a measurement.
- The result of an operator operating on a state vector is a new state vector.
- A measurement, on the other hand, is the result obtained when an apparatus interacts with a physical system. In the case of spin, for example, it is +1 or -1 .
- The result of an operator operating on a state vector (i.e. a new state vector) is definitely not the same as the result of a measurement (for example, the +1 or -1 obtained when a spin is measured).
- The state that results after an operator operates on a state vector is different than the state resulting after a measurement.
Here is an example of the latter. Suppose we prepare a spin in the direction and measure it with our apparatus pointed in the direction.
The state, , that describes an electron spin prepared in the direction and measured in the direction is

Acting on this state vector with gives us
![\begin{array}{rcl} \sigma_z \ket{r} &=& \frac{1}{\sqrt 2}\sigma_z\ket{u} + \frac{1}{\sqrt 2}\sigma_z\ket{d}\\ &=& \frac{1}{\sqrt 2} \mqty[1&0\\0&-1] \mqty[1\\0] + \frac{1}{\sqrt 2} \mqty[1&0\\0&-1] \mqty[0\\1]\\ &=& \frac{1}{\sqrt 2} \mqty[1\\0] + \frac{1}{\sqrt 2} \mqty[0\\-1]\\ &=& \frac{1}{\sqrt 2} \mqty[1\\0] - \frac{1}{\sqrt 2} \mqty[0\\1]\\ &=& \frac{1}{\sqrt 2}\ket{u} - \frac{1}{\sqrt 2}\ket{d} \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-648f037aa5f1ada0d244917fdcc31f0f_l3.png "Rendered by QuickLaTeX.com")
But this is definitely not the state that results from a measurement. The state that the spin is left in after a measurement would be if the measurement is +1 or if the measurement is -1.
So what does this new state vector that results after an operator operates on an original state vector have to do with measurement? It allows us to calculate the probability of each possible outcome of a measurement.
Deriving σ n
The original experimental results we sought to describe mathematically were
the probabilities of a spin being measured as spin up (+1) and spin down (-1) given 1) that the spin was prepared in the x-z plane at
To figure this out, what we’ll do is construct an operator that is associated with measurement of a spin oriented at any direction in space. We can represent the direction in space in which to measure as  which is a unit vector and has components
which is a unit vector and has components  ,
,  and
and  . We won’t go through a formal proof of it but the operator associated with measurement of spin in the direction (which we’ll call
. We won’t go through a formal proof of it but the operator associated with measurement of spin in the direction (which we’ll call  ) behaves like a vector. Therefore, we can say
) behaves like a vector. Therefore, we can say

where the  are just numbers. Therefore:
are just numbers. Therefore:
![\begin{array}{rcl} \sigma_n &=& \mqty[0&1\\1&0] n_x + \mqty[0&-i\\i&0] n_y+ \mqty[1&0\\0&-1] n_z \\ &=& \mqty[0&n_x\\n_x&0] + \mqty[0&-in_y\\in_y&0] + \mqty[n_z&0\\0&-n_z] \\ &=& \mqty[n_z&n_x-in_y\\n_x+in_y&-n_z] \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-dfe2447b56da2c816cc738e7750de75c_l3.png "Rendered by QuickLaTeX.com")
To solve our problem, we’ll need to find the eigenvalues and eigenvectors of our matrix, . Also, we’ll use spherical coordinates. A quick visual review of spherical coordinates and reminder of how they relate to Cartesian coordinates is given in the following diagram:
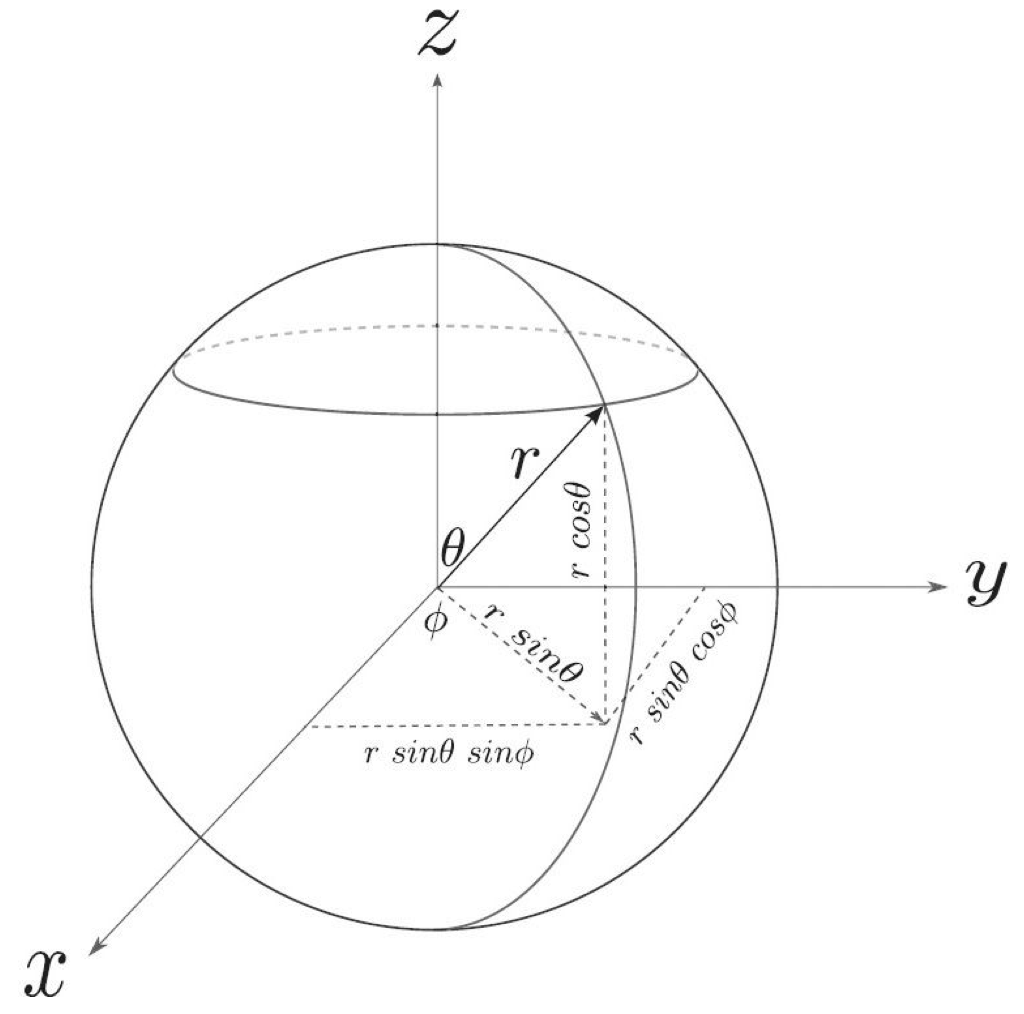
We’re dealing with a unit vector, . Therefore  . So, from the diagram,
. So, from the diagram,



Substituting the above values into , we get:
![\sigma_n=\mqty[\cos\theta & \sin\theta \cos\phi-i\sin\theta \sin\phi\\\sin\theta \cos\phi+i\sin\theta \sin\phi & -\cos\theta]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-02f16be8a8ae443975746bb98d3c28ed_l3.png "Rendered by QuickLaTeX.com")
Since we’re dealing with an that is in the x-z plane,


Substituting these values into , we have:
![\begin{array}{rcl} \sigma_n=\sigma_n&=&\mqty[\cos\theta & \sin\theta \cos\phi-i\sin\theta \sin\phi\\\sin\theta \cos\phi+i\sin\theta \sin\phi & -\cos\theta]\\ \, &\,& \, \\ &=& \mqty[\cos\theta & (\sin\theta)(1)-(i\sin\theta) (0)\\ (\sin\theta) (1)+(i\sin\theta)(0) & -\cos\theta]\\ \, &\,& \, \\ &=&\mqty[\cos\theta & \sin\theta \\ \sin\theta & -\cos\theta] \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f35ae11b27e0a4c4db2789fd6eaadb88_l3.png "Rendered by QuickLaTeX.com")
If  , then the calculations become more complicated. To see these calculations, click
, then the calculations become more complicated. To see these calculations, click

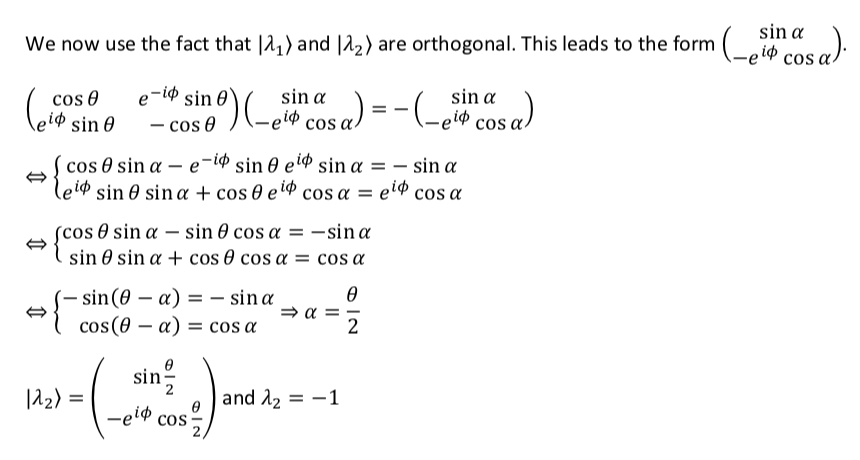
Continuing with our current simpler problem, calculation of the eigenvalues and eigenvectors of goes as follows:
Our matrix is filled with sines and cosines. Therefore, our eigenvectors  and
and  (which we’ll, at first, collectively refer to as
(which we’ll, at first, collectively refer to as  ) are likely to be something like
) are likely to be something like ![\mqty[\cos\alpha \\ \sin\alpha]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f9af51f7c85fd12d6e49cbf597526ed7_l3.png "Rendered by QuickLaTeX.com") . We don’t know
. We don’t know  ; the is what we have to find – in terms of
; the is what we have to find – in terms of  . So we write eigenvalue equations:
. So we write eigenvalue equations:
![\begin{array}{rcl} \sigma_n \ket{\lambda}&=& \lambda\ket{\lambda}\\ \, &\,& \, \\ \mqty[\cos\theta & \sin\theta\\ \sin\theta & -\cos\theta]\mqty[\cos\alpha \\ \sin\alpha]&=&\lambda\mqty[\cos\alpha \\ \sin\alpha] \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-3f572fdaa253fecdd4d04a21a8870c76_l3.png "Rendered by QuickLaTeX.com")
Doing matrix multiplication leaves us with 2 equations in 2 unknowns:

and

From the page on this site entitled Trigonometry Identities, we know that


So


Divide both sides of the top equation by  and both sides of the bottom equation by
and both sides of the bottom equation by  . That gives us
. That gives us


The left-hand side of both of the above equations equal  . Therefore, they are equal to each other:
. Therefore, they are equal to each other:

Multiply both sides of this equation by  . We get
. We get

Subtract  from both sides. That leaves us with
from both sides. That leaves us with

Let  . Substituting this into the above equation gives us
. Substituting this into the above equation gives us

Using our trigonometry identities again

But . Thus,
![\sin[\alpha - (\theta - \alpha)] = \sin(2\alpha-\theta)=0](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-19869b243d5289fe0eb69142bbc3627b_l3.png "Rendered by QuickLaTeX.com")
We know that there are 2 conditions in which  :
:


It follows, then, that  when
when


So that leaves us with the opportunity to calculate 2 eigenvalues, which is what we want. Recall that
We’ll arbitrarily use the top equation to calculate our eigenvalues and eigenvectors.
First,

and
![\ket{\lambda_1} = \mqty[\cos\alpha \\ \sin\alpha] = \mqty[\cos\frac{\theta}{2} \\ \sin\frac{\theta}{2}]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-51cf6178b81fdbc998f0c11260d55619_l3.png "Rendered by QuickLaTeX.com")
Second,

To solve the last step in the above equation, we need to figure out alternative expressions for  and
and  . To do this, we need to use the following trigonometry identities:
. To do this, we need to use the following trigonometry identities:


Thus,

Now for the eigenvector:
![\ket{\lambda_2} = \mqty[ \cos (\frac{\theta}{2} + \frac{\pi}{2}) \\ \sin (\frac{\theta}{2} + \frac{\pi}{2}) ]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-0e6fd1e952e1c52c1f72ac1fbe586e97_l3.png "Rendered by QuickLaTeX.com")
To solve this equation, we have to find expressions for  and
and  . To do this, we let
. To do this, we let  and use the Trigonometry Identities
and use the Trigonometry Identities


When we do this, we get
![\ket{\lambda_2} = \mqty[ \cos (\frac{\theta}{2} + \frac{\pi}{2}) \\ \sin (\frac{\theta}{2} + \frac{\pi}{2}) ] = \mqty [ -\sin \frac{\theta}{2} \\ \cos \frac{\theta}{2}]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a210d5aebb44a0afd9a4ccb87d95b19f_l3.png "Rendered by QuickLaTeX.com")
Now that we’ve got the eigenvalues and eigenvectors, we can calculate the probability of measuring spin up,  , as follows:
, as follows:
![\begin{array}{rcl} P(+1)&=&\braket{\lambda_1}{u}\braket{u}{\lambda_1}\\ &=& \mqty[\cos\frac{\theta}{2} & \sin\frac{\theta}{2}]\mqty[1\\0]\mqty[1&0]\mqty[1&0]\mqty[\cos\frac{\theta}{2} \\ \sin\frac{\theta}{2}] \\ &=& \cos\frac{\theta}{2} \cdot \cos\frac{\theta}{2} \\ &=& (\cos\frac{\theta}{2})^2 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-fbaf07569243f96dd7bd9fd8f152266c_l3.png "Rendered by QuickLaTeX.com")
We calculate the probability of measuring spin down,  , in a similar fashion:
, in a similar fashion:
![\begin{array}{rcl} P(-1)&=&\braket{\lambda_2}{u}\braket{u}{\lambda_2}\\ &=& \mqty[-\sin\frac{\theta}{2} & \cos\frac{\theta}{2}]\mqty[1\\0]\mqty[1&0]\mqty[-\sin\frac{\theta}{2} & \cos\frac{\theta}{2}] \\ &=& -\sin\frac{\theta}{2} \cdot -\sin\frac{\theta}{2} \\ &=& (\sin\frac{\theta}{2})^2 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-51469727b65e7a2a6fe827d45bfee3ca_l3.png "Rendered by QuickLaTeX.com")
Finally, we prepare our spin in the direction from the =z-axis toward the +x-axis. Then we measure in the +z direction which is  . We already have expressions for and . Now all we have to do is plug into those expressions. When we do, we obtain:
. We already have expressions for and . Now all we have to do is plug into those expressions. When we do, we obtain:

and

We haven’t discussed it previously but if we repeat this experiment an infinite number of times, then the average value of our measurements (called the expectation value) will be what would be predicted by classical mechanics. Experimental data indicates that, for spin, that this expectation value is given by the cosine of the angle between the direction at which the spin is prepared and the direction at which it is measured. The mathematical expression for the expectation value is to enclose the entity to be measured (which is an operator, also called an observable) in brackets. In our case, the angle of between preparation and measurement is  . Therefore, experiments suggest that the exception value should be
. Therefore, experiments suggest that the exception value should be  . Let’s now see if our mathematical predictions match the experimental results.
. Let’s now see if our mathematical predictions match the experimental results.
The formula for the expectation value of an observable, , in quantum mechanics is just the same as the general formula for average value; we multiply the value of each measurement times the probability of its occurrence then take the sum of each of these products:
 where
where
- are the eigenvalues (i.e., the value of the measurements)
 are the probabilities of occurrence of each
are the probabilities of occurrence of each
So,

There is another trigonometry identity that states

Therefore,

just as we had hoped.
We could also plug in the values we got for  and
and  . When we do, we get
. When we do, we get

again, agreeing with experiment.
Other operators and wave functions
We’ve spoken so far about a simple physical system – spin. However, the mathematical tools that describe spin are the same ones that are used in other physical systems. Therefore, we examined this system in detail so that readers who are completely new to this subject have some idea about what we are talking about when we discuss these things – especially operators and wave functions – in what follows.
When we talked about spin, we talked about a discrete system. That is, the vectors used to describe states and wave functions, for example, had a finite number of dimensions, namely 2. Likewise, operators (or observables) were matrices with a finite number of entries. However, continuous functions can form vector spaces like discrete vectors. The difference is that functions have an infinite number of dimensions.
The observables we’ll be talking about in our proofs of the equations of Bohmian mechanics, and the operators that represent them, are involved with continuous variables. Specifically, they are position, momentum and energy. We’ll examine each one, in turn.
Position
By position, we mean position in space. Of course, position is a continuous variable. We’ll call the operator that’s involved in the measurement of position  . When it acts on a wave function, what it does is multiply the wave function by the value of a position in space, which we’ll call . So
. When it acts on a wave function, what it does is multiply the wave function by the value of a position in space, which we’ll call . So

We need to examine the eigenvalues and eigenstates of the position operator. The eigenvalue equation is

In terms of wave functions, this becomes:

Rearranging, we get

For this equation to be true, either  or
or  must be zero. The case where is the zero vector is uninteresting. We want to evaluate the case where
must be zero. The case where is the zero vector is uninteresting. We want to evaluate the case where  . This only happens when
. This only happens when

So for to be nonzero, is zero at every position except one:  . This sounds a lot like the Dirac delta function,
. This sounds a lot like the Dirac delta function,  .
.
The Dirac delta function is a function that has no width along the x-axis, is infinitely high in the y-direction and has an area of 1 under it (i.e., it is infinitely concentrated at one point along the x-axis).  is infinitely concentrated at
is infinitely concentrated at  . Therefore,
. Therefore,  is infinitely concentrated at
is infinitely concentrated at  . (This is because
. (This is because  which makes
which makes  ).
).
The eigenstate (or in this instance, eigenfunction) of , then, is

This makes sense since, by definition, an eigenstate or eigenfunction is the state/function where the outcome of a measurement is – with 100% certainty – its associated eigenvalue.
We can make the same argument for eigenvalues  , indeed, for every point on the x-axis. So every point on the x-axis is an eigenvalue.
, indeed, for every point on the x-axis. So every point on the x-axis is an eigenvalue.
Wave functions that are not eigenfunctions must specify a probability amplitude for every eigenvalue. Since every point on the x-axis is an eigenvalue, such a wave function must specify a probability amplitude for a particle to be found at every point on the x-axis. There are an infinite number of x-axis points, thus, the wave functions for position are continuous functions.
Momentum
Momentum, in quantum mechanics, is a little more complicated than position. Specifically, the connection between the momentum operator in quantum mechanics and the classical notion of momentum (i.e.,  ) is less intuitive than the relationship between the quantum position operator and its classical counterpart. However, with some work, the connection will become apparent.
) is less intuitive than the relationship between the quantum position operator and its classical counterpart. However, with some work, the connection will become apparent.
The quantum momentum operator is

To prove that it is a quantum operator, we have to prove 2 things:
 is a linear operator
is a linear operator- is a Hermitian operator
We’ll prove each in turn. The way that we’ll do this is to prove the above properties for the differential operator,  . Because is just multiplied by a constant, the properties that apply to also apply to .
. Because is just multiplied by a constant, the properties that apply to also apply to .
Proof: P is linear
This proof is copied directly from the following link (exercise 8.1):

Proof: p is hermitian
This proof is taken from Susskind and Friedman, Quantum Mechanics: The Theoretical Minimum, chapter 8.
We note that, if an operator  is Hermitian, and we sandwich it between a bra and a ket vector, then the quantities we get should be complex conjugates of each other:
is Hermitian, and we sandwich it between a bra and a ket vector, then the quantities we get should be complex conjugates of each other:

Notice that uppercase  and
and  are used in this equation while lowercase
are used in this equation while lowercase  and
and  are used elsewhere. Susskind and Friedman use capital Greek letters to represent state vectors and lower case Greek letters to represent wave functions, which they define as being a state vector expressed in a given basis (which is determined by and operator. I’m not certain that it makes a difference in this proof but they use this convention in there proof so we’ll just roll with it here.
are used elsewhere. Susskind and Friedman use capital Greek letters to represent state vectors and lower case Greek letters to represent wave functions, which they define as being a state vector expressed in a given basis (which is determined by and operator. I’m not certain that it makes a difference in this proof but they use this convention in there proof so we’ll just roll with it here.
Anyway let’s start by check to see of this works with the position operator, .
Recalling that
we find the following to be true:

and

Because is real, the above integrals are complex conjugates of each other, and therefore, is Hermitian.
What about ? We have

and

In this form, we cannot definitively determine whether the above integrals are complex conjugates of each other. We need to make a direct comparison. To do this, we need to make use of integration by parts. Here is a quick review of this technique:

State and wave functions are normalized. Thus, they must go to zero at infinity. Integrals of such wave function span entire axises meaning the limits of integration are from  to
to  . Therefore,
. Therefore,  . So the term
. So the term  “disappears” and we’re left with
“disappears” and we’re left with
 or
or  .
.
Applying this to our original problem, let
 be analogous to
be analogous to 
 be analogous to
be analogous to
Then,

So now we have
and

From this, we can see that

In other words,

instead of

which would be the case if were Hermitian. To make it Hermitian, we would need to change to  .
.
Why? We know from the above argument that

Now multiply by and take the transpose:

So we have  which, by definition, makes Hermitian.
which, by definition, makes Hermitian.
Quantum Momentum operator
However, if we assume that the quantum momentum operator approaches the classical notion of momentum, then the units of the quantum momentum operator should be the same as those of momentum in classical physics. If so, then  doesn’t fit the bill.
doesn’t fit the bill.
Let,
- L = length
- M = mass
- T = time
The units of are  . The units of momentum are
. The units of momentum are  . To make them the same, we multiply by Planck’s constant,
. To make them the same, we multiply by Planck’s constant,  , which has units
, which has units  . We have
. We have

which, of course, are the units of momentum in classical physics. So the momentum operator in quantum mechanics is

Energy
The total energy of a system in classical mechanics is given by the Hamiltonian. Similarly, the linear operator for energy in quantum mechanics is the quantum Hamiltonian. Its form varies with the type of physical system we’re considering. For example,
The quantum Hamiltonian for a harmonic oscillator (i.e., a system that behaves like a mass attached to a spring) is:
 where
where
 is the quantum Hamiltonian
is the quantum Hamiltonian- is the quantum operator for momentum
 is mass
is mass
 is the spring constant
is the spring constant- is the position operator
The quantum Hamiltonian for a charged particle in an electromagnetic field is:

I won’t even tell you what all of these symbols mean because it’s not important for our discussion here – you get the picture.
However, what is important to our derivation of Bohmian mechanics is the quantum operator for a particle moving in a potential energy field. In this case the potential is generic – it could be any kind of potential energy. Like many quantum Hamiltonians, it is similar to the classical Hamiltonian for the specific quantity it represents. It is given by:
 where
where
- , and are as defined above
 is a vector that represents position; it could be in the x, y or z direction
is a vector that represents position; it could be in the x, y or z direction is time
is time is the potential energy, which depends on both spatial position and time; it, itself, is an operator that multiplies whatever it acts upon by the potential energy at position and time,
is the potential energy, which depends on both spatial position and time; it, itself, is an operator that multiplies whatever it acts upon by the potential energy at position and time,
It should be noted that, in the strict Schrodinger formulation of quantum mechanics, the Hamiltonian is constant and state vectors(functions) vary with time. By contrast, in the Heisenberg formulation, the Hamiltonian varies with time and state vectors(functions) are constant. However, there are hybrid versions in which the Hamiltonian and/or state function vary with time. These formulations are all equivalent. Bohm, in his derivation, uses a hybrid version in which position and potential energy both vary with position and time.